hook点
大部分是挂载位置是tc,tc是网络协议栈初始处理挂载点
// linux source code: dev.c
__netif_receive_skb_core
| list_for_each_entry_rcu(ptype, &ptype_all, list) {...} // packet capture
| do_xdp_generic // handle generic xdp
| sch_handle_ingress // tc ingress
| tcf_classify
| __tcf_classify // ebpf program is working here
如果没有下发policy,xdp就不会挂载各类filter程序
网络设备
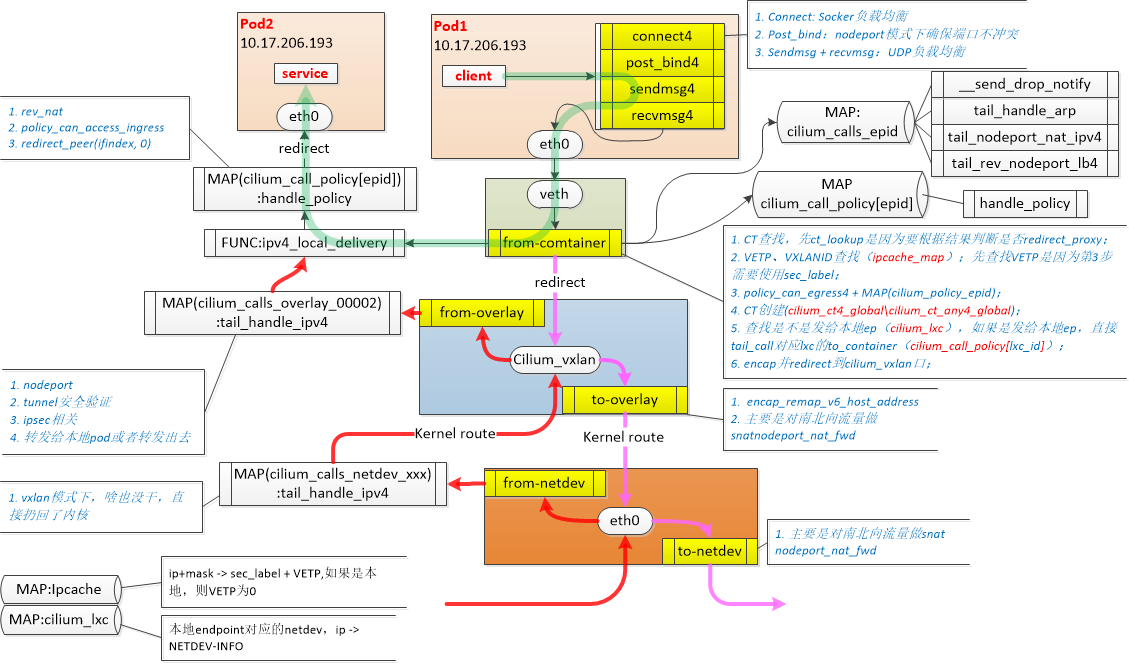
cillium的网络方案不像常规的网桥模式(ovs,linux bridge),datapath不是一个完整的run to completion,而是分散在各个虚拟接口上,类似pipeline模式
cillium_host: 集群内所有podCIDR的网关,地址对容器可见
cilium_net: cilium_host的veth对,ipvlan模式才会用到?
clilium_vxlan: 用来提供Pod跨节点通信overlay封装
lxcXXXX: 容器veth对在主机侧的接口
同节点pod2pod
cillium_host是所有pod的网关,因此会先arp request该地址。arp相应其实是在lxc处被代答了,arp报文不会走到cillium_host
// bpf_lxc.c
__section_entry
int cil_from_container(struct __ctx_buff *ctx)
{
...
case bpf_htons(ETH_P_ARP):
ret = tail_call_internal(ctx, CILIUM_CALL_ARP, &ext_err);
break;
...
}
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_ARP)
int tail_handle_arp(struct __ctx_buff *ctx)
{
union macaddr mac = THIS_INTERFACE_MAC;
union macaddr smac;
__be32 sip;
__be32 tip;
/* Pass any unknown ARP requests to the Linux stack */
if (!arp_validate(ctx, &mac, &smac, &sip, &tip))
return CTX_ACT_OK;
/*
* The endpoint is expected to make ARP requests for its gateway IP.
* Most of the time, the gateway IP configured on the endpoint is
* IPV4_GATEWAY but it may not be the case if after cilium agent reload
* a different gateway is chosen. In such a case, existing endpoints
* will have an old gateway configured. Since we don't know the IP of
* previous gateways, we answer requests for all IPs with the exception
* of the LXC IP (to avoid specific problems, like IP duplicate address
* detection checks that might run within the container).
*/
if (tip == LXC_IPV4)
return CTX_ACT_OK;
return arp_respond(ctx, &mac, tip, &smac, sip, 0);
}
普通ipv4报文,走handle_ipv4_from_lxc
// bpf_lxc.c
cil_from_container(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx) // lookup ct, store in ct_buffer, zero indexed
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id) // do policy if ct est/new, ct_create if ct_status is new
| __lookup_ip4_endpoint(ip4) // get local endpoint (pod or host)
| ipv4_local_delivery(...)
| ipv4_l3(ctx,...) // ttl-1 & update mac header
| tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id) // jump to destination pod's bpf program for policy enforcement
| handle_policy(...)
| tail_ipv4_ct_ingress_policy_only(...)
| tail_ipv4_policy(...)
| ipv4_policy(...)
| redirect_ep(...) // redirect to dst iface
相关的map
CT_MAP_(TCP/ANY)(4/6): conntrack
cilium_lxc:本机endpoint
cilium_call_policy:pod ep对应的policy, BPF_MAP_TYPE_PROG_ARRAY
流程关键点是查cilium_lxc来判断是否local ep,然后做基本的二层转发
redirect_ep会根据宏定义判断最后调用redirect_peer(发往ifindex的peer,也就是容器里的eth0)还是redirect(发往ifindex,也就是lxc)。
5.10版本以上的内核建议开启bpf的host_routing模式。如果host_routing模式是legacy,则不会调用redirect_ep,而是返回CTX_ACT_OK。之后通过内核路由表转发到cillium_host设备上,走cil_from_netdev流程。这样流量会被内核路由表和iptables影响,且走了没有用的流程,性能较低。
一般情况下是直接redirect_peer发往对端eth0,因为对端ep的policy已经在handle_policy中的尾调用执行完毕了。
对端ep的ingress一般不会加载bpf代码,若走redirect,后续还会执行对端ep的ingress流程。
cil_to_container(struct __ctx_buff *ctx)
| tail_ipv4_to_endpoint
| ipv4_policy
| redirect_ep(ctx, ifindex, from_host) // redirect to dst iface
值得一提的是TAIL_CT_LOOKUP4(ID, NAME, DIR, CONDITION, TARGET_ID, TARGET_NAME)这个宏定义
- 构造tuple查询ct
- 将ct信息存到CT_TAIL_CALL_BUFFER4,index是0,便于后续处理流程读取
- 根据宏定义的CONDITION,决定是否执行下一个尾调用
总共有三处
TAIL_CT_LOOKUP4(CILIUM_CALL_IPV4_CT_EGRESS, tail_ipv4_ct_egress, CT_EGRESS,
is_defined(ENABLE_PER_PACKET_LB),
CILIUM_CALL_IPV4_FROM_LXC_CONT, tail_handle_ipv4_cont)
// tail_ipv4_ct_egress
TAIL_CT_LOOKUP4(CILIUM_CALL_IPV4_CT_INGRESS_POLICY_ONLY,
tail_ipv4_ct_ingress_policy_only, CT_INGRESS,
__and(is_defined(ENABLE_IPV4), is_defined(ENABLE_IPV6)),
CILIUM_CALL_IPV4_TO_LXC_POLICY_ONLY, tail_ipv4_policy)
// tail_ipv4_ct_ingress_policy_only
TAIL_CT_LOOKUP4(CILIUM_CALL_IPV4_CT_INGRESS, tail_ipv4_ct_ingress, CT_INGRESS,
1, CILIUM_CALL_IPV4_TO_ENDPOINT, tail_ipv4_to_endpoint)
// tail_ipv4_ct_ingress
跨节点pod2pod
在handle_ipv4_from_lxc时,__lookup_ip4_endpoint没有查到本地的ep,走encap_and_redirect_lxc
// bpf_lxc.c
cil_from_container(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx) // lookup ct, store in ct_buffer, zero indexed
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| encap_and_redirect_lxc(...) // tunnel_endpoint is fetched from cilum_ipcache map
| __encap_and_redirect_with_nodeid(...)
| __encap_with_nodeid(...)
| ctx_set_encap_info(ctx, ...) // redirect to vxlan netdev
encap_and_redirect_with_nodeid还会执行ipsec的封装,若不开启则转发到对应的tunnel device
tunnel_endpoint是查找IPCACHE_MAP得到的,该表类似阿里的vmnc表
$ cilium map get cilium_ipcache
Key Value State Error
10.0.2.158/32 identity=13789 encryptkey=0 tunnelendpoint=172.18.0.5 sync
10.0.1.214/32 identity=19140 encryptkey=0 tunnelendpoint=172.18.0.5 sync
10.0.1.213/32 identity=62536 encryptkey=0 tunnelendpoint=0.0.0.0 sync
0.0.0.0/0 identity=2 encryptkey=0 tunnelendpoint=0.0.0.0 sync
172.18.0.4/32 identity=1 encryptkey=0 tunnelendpoint=0.0.0.0 sync
10.0.1.116/32 identity=9049 encryptkey=0 tunnelendpoint=0.0.0.0 sync
ctx_set_encap_info最终会调用helper skb_set_tunnel_key,再返回CTX_ACT_REDIRECT,由内核转到对应的tunnel设备上
之后执行tunnel设备的tc egress: cil_to_overlay。这边主要是做访问nodeport时,重定向发往remote ep时的snat,与pod2pod流程无关
之后内核tunnel设备会进行overlay封装,发往物理网口netdev
接收端节点,tunnel设备收到overlay报文后,走tunnel设备的ingress tc
此处已经时tunnel设备解封装后的报文,最后走ipv4_local_delivery,和同节点pod2pod后面的流程一样
// bpf_overlay.c
| cil_from_overlay(struct __ctx_buff *ctx)
| handle_ipv4(ctx, &src_identity)
| ipcache_lookup4(...) // get dest identity
| ipv4_local_delivery(...) // deliver to local identity, same steps with previous call stack
node2pod
在发送端,根据路由表,pod网段先发送到cillium_host设备
$ ip r
10.0.0.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197 mtu 1450
10.0.1.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197
10.0.2.0/24 via 10.0.1.197 dev cilium_host src 10.0.1.197 mtu 1450
tail_handle_ipv4之后流程类似pod2pod,本节点就ipv4_local_delivery,跨节点走encap_and_redirect_with_nodeid
// bpf_host.c
cil_from_netdev(struct __ctx_buff *ctx)
| do_netdev(ctx, proto, from_host)
| tail_handle_ipv4_from_host(struct __ctx_buff *ctx)
| tail_handle_ipv4(...)
| handle_ipv4(...)
| encap_and_redirect_with_nodeid(...) // encap and send to remote tunnel endpoint
接收端cilium_vxlan的ingress方向,lookup_ip4_endpoint查询bpf map cilium_lxc判断是node上的cilium_host
// bpf_overlay.c
| tail_handle_ipv4(struct __ctx_buff *ctx)
| handle_ipv4(ctx, &src_identity)
| ep = lookup_ip4_endpoint(ip4) // look up endpoint from cilium_lxc
| if (ep->flags & ENDPOINT_F_HOST)
| goto to_host
| to_host:
| ipv4_l3(...) // update ttl and mac addresses
| ctx_redirect(ctx, HOST_IFINDEX, 0) // redirect to cilium_host
lb service
替代内核的 NodePort, LoadBalancer services and services with externalIPs的实现
pod2service
首包流程
cil_from_container
| tail_handle_ipv4
| __per_packet_lb_svc_xlate_4
| lb4_extract_tuple // 取五元组(pod --> svc)
| lb4_lookup_service // 查svc,能查到
| lb4_local // 查ct,执行DNAT
| ct_lookup4 //根据五元组查询service类型连接状态(第一个包,所以查询不到)
| lb4_select_backend_id //根据算法选择一个service后端
| ct_create4 //创建service类型的连接状态(连接状态关联了service后端,后续同一个连接的数据包将导向用一个后端)
| lb4_xlate // 执行DNAT(修改数据包的目的地址为endpoint的地址)
| tail_call_internal(ctx, CILIUM_CALL_IPV4_CT_EGRESS, ext_err) // 保存ct到ct_buffer
| tail_handle_ipv4_cont
| handle_ipv4_from_lxc(ctx, &dst_id)
| encap_and_redirect_lxc(...) // tunnel_endpoint is fetched from cilum_ipcache map
| __encap_and_redirect_with_nodeid(...)
| __encap_with_nodeid(...)
| ctx_redirect(ctx, ENCAP_IFINDEX, 0) // redirect to vxlan netdev
tail_handle_ipv4 过程中查service表,若查到走dnat流程
dnat之后的流程和pod2pod流程基本一致
reply流程
主要是做反向DNAT
// bpf_lxc.c
| cil_to_container
| tail_ipv4_to_endpoint
| ipv4_policy
| lb4_rev_nat // ct_state == CT_REPLY, do reverse nat
| map_lookup_elem(&LB4_REVERSE_NAT_MAP, ...) // lookup reverset nat map
| __lb4_rev_nat // replace source IP
| redirect_ep(ctx, ifindex, from_host) // redirect to dest iface
node2service
与pod2service的区别是,除了DNAT还要做一次SNAT,源地址统一改成node的地址
这是由于访问service的流量,可能是节点上来的,也有可能是外部来的。无论如何,都snat成nodeport地址
相应的,做反向DNAT之前要先做反向SNAT
lb代码加载位置
默认
cil_from_netdev加载在cillium_host上开启nodeport:
cil_from_netdev会加载到物理口的tc egress上开启 LB&NodePort XDP加速:启动后编译选项
-DENABLE_NODEPORT_ACCELERATION=1之后bpf_xdp.c会编译尾调用CILIUM_CALL_IPV4_FROM_NETDEV
最终
cil_xdp_entry流程中会执行lb流程
无论是上述哪种加载流程,最终都会执行nodeport_lb4
入向流量
- SVC lookup? –> DNAT
- endpoint remote?
- tunnel or local?
- SNAT
- fib_lookup
- redirect
nodeport_lb4
lb4_lookup_servic //查询该流量是否属于对应的service前端
lb4_local //执行lb算法选择service后端,进行DNAT
ct_lookup4 //根据五元组查询service类型连接状态(第一个包,所以查询不到)
lb4_select_backend_id //根据算法选择一个service后端
ct_create4 //创建service类型的连接状态(连接状态关联了service后端,后续同一个连接的数据包将导向用一个后端)
lb4_xlate //执行DNAT(修改数据包的目的地址为service后端的地址)
ct_lookup4 //根据五元组查询EGRESS(入)类型连接状态(注意此时五元组中的目的地址已经发生变化)(反转五元组)
ct_create4 //创建连接状态(使用反转五元组创建,用于反向DNAT)
ep_tail_call(ctx, CILIUM_CALL_IPV4_NODEPORT_NAT) //执行尾调用,跳转到CILIUM_CALL_IPV4_NODEPORT_NAT
tail_nodeport_nat_ipv4
snat_v4_proces //执行SNAT
snat_v4_handle_mapping // 处理SNAT映射
snat_v4_lookup // 根据五元组查询SNAT映射(查不到)
snat_v4_new_mapping //新建SNAT映射,首先调整原来的端口,若发生冲突则重新选择(会根据正向和反向分别建立映射,反向搜索)
snat_v4_rewrite_egress // 执行实际的SNAT动作(修改源地址、源端口、修正checksum)
fib_lookup // 查询路由表
eth_store_daddr/eth_store_saddr // 设置mac地址
ctx_redirect // 发送数据包
反向流量
- rev-SNAT xlation
- rev-DNAT xlation
- fib_lookup
- redierct
nodeport_lb4
lb4_lookup_service // 查不到
ep_tail_call(ctx, CILIUM_CALL_IPV4_NODEPORT_NAT_INGRESS)
tail_nodeport_nat_ingress_ipv4
snat_v4_rev_nat // 执行SNAT
snat_v4_rev_nat_handle_mapping //校验endpoint-->lip(endpoint) 的snat entry是否存在
__snat_lookup // 查询SNAT映射,查询到了正向流建立SNAT映射
snat_v4_rewrite_headers // 执行rev-SNAT:endpoint --> client
ep_tail_call(ctx, CILIUM_CALL_IPV4_NODEPORT_REVNAT)
nodeport_rev_dnat_ingress_ipv4
ct_lookup4 // 查询连接状态, CT_REPLY
lb4_rev_nat// 执行rev-DNAT
map_lookup_elem(&LB4_REVERSE_NAT_MAP, &ct_state→rev_nat_index)// 查询rev-DNAT所需的原始IP端口(即service的IP及端口)
__lb4_rev_nat// 执行rev-DNAT,修改源端口、源地址、checksum
ipv4_l3 // ttl--
fib_lookup// 查询路由表
eth_store_daddr/eth_store_saddr //设置mac地址
ctx_redirect // 发送数据包
ct表
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH); // LRU哈希表
__type(key, struct ipv4_ct_tuple); // 哈希key
__type(value, struct ct_entry); // 哈希value
__uint(pinning, LIBBPF_PIN_BY_NAME); //固定在文件系统中
__uint(max_entries, CT_MAP_SIZE_TCP); // 最大条目数
} CT_MAP_TCP4 __section_maps_btf;
lb realserver
struct lb4_backend {
__be32 address; /* Service endpoint IPv4 address */
__be16 port; /* L4 port filter */
__u8 proto; /* L4 protocol, currently not used (set to 0) */
__u8 flags;
__u16 cluster_id; /* With this field, we can distinguish two
* backends that have the same IP address,
* but belong to the different cluster.
*/
__u8 zone;
__u8 pad;
};
通过cluster_id解决ip重叠问题
snat表
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__type(key, struct ipv4_ct_tuple);
__type(value, struct ipv4_nat_entry);
__uint(pinning, LIBBPF_PIN_BY_NAME);
__uint(max_entries, SNAT_MAPPING_IPV4_SIZE);
} SNAT_MAPPING_IPV4 __section_maps_btf;
pod2external
// bpf_lxc.c
cil_from_container(struct __ctx_buff *ctx)
| ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC)
| tail_handle_ipv4(struct __ctx_buff *ctx)
| __tail_handle_ipv4(ctx)
| tail_handle_ipv4_cont(struct __ctx_buff *ctx)
| handle_ipv4_from_lxc(ctx, &dst_id)
| ret = encap_and_redirect_lxc(...)
| if (ret == DROP_NO_TUNNEL_ENDPOINT) goto pass_to_stack
| pass_to_stack: ipv4_l3(...)
| return to stack
remote endpoint未查到,返回DROP_NO_TUNNEL_ENDPOINT
之后发往内核协议栈,内核可能有iptables规则nat成nodeport
接收回包时,内核根据出方向Masquerade的情况做反向nat,之后查内核路由表发给cilium_host。最后走cil_from_netdev,转给对应的pod
参考资料
Life of a Packet in Cilium: Discovering the Pod-to-Service Traffic Path and BPF Processing Logics