首先需要了解grpc框架的一些概念,这边引用网上的一张图
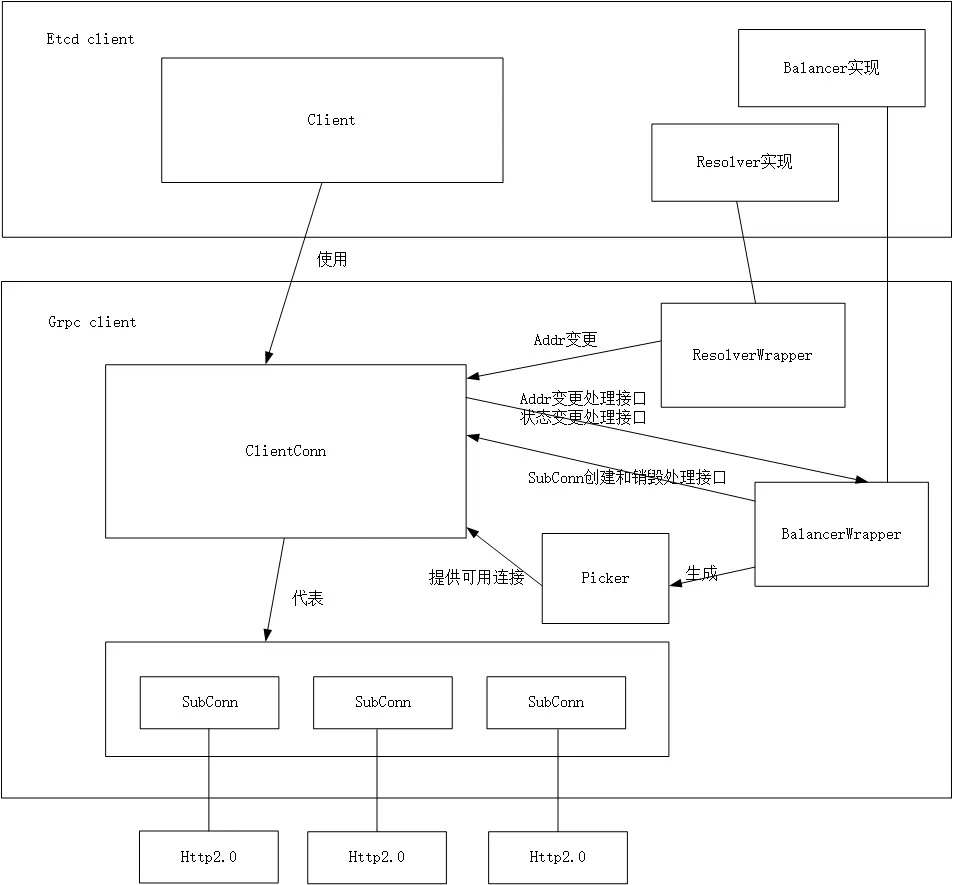
Resolver
提供一个用户自定义的解析、修改地址的方法,使得用户可以自己去实现地址解析的逻辑、做服务发现、地址更新等等功能。
- 将Endpoints里的ETCD服务器地址(127.0.0.1:2379这种格式)做一次转换传给grpc框架。也可以自己重新写此resolver,做服务发现功能。例如etcd服务器地址写nacos之类的地址,在resolver中写好转换逻辑。
- 调用ClientConn的ParseServiceConfig接口告诉endpoints的负载策略是轮询
Balancer
- 管理subConns,并收集各conn信息,更新状态至ClientConn
- 生成picker(balancer)的快照,从而ClientConn可以选择发送rpc请求的subConn
此处etcd client没有实现balancer,默认使用grpc提供的轮询的balancer
重试策略
与一般的c-s模型不同,etcd client的重试是针对集群的重试。单个节点的断连不会造成所有节点的重连。
重试机制
一般的重试是对同一个节点进行重试,但etcd client的自动重试不会在ETCD集群的同一节点上进行,是轮询重试集群的每个节点。重试时不会重新建连,而是使用balancer提供的transport。transport的状态更新与这一块的重试是通过balancer解耦的。
重试条件
etcd unary拦截器
拦截器类似http里的中间件的概念,在发送实际请求之前对报文进行篡改。一般用来添加认证,日志记录,缓存之类的功能。
此处etcd的一元拦截器主要做了自动重试的功能,且只会重试一些特定的错误(DeadlineExceeded, Canceled,ErrInvalidAuthToken)
func (c *Client) unaryClientInterceptor(optFuncs ...retryOption) grpc.UnaryClientInterceptor {
...
if isContextError(lastErr) {
if ctx.Err() != nil {
// its the context deadline or cancellation.
return lastErr
}
// its the callCtx deadline or cancellation, in which case try again.
continue
}
if callOpts.retryAuth && rpctypes.Error(lastErr) == rpctypes.ErrInvalidAuthToken {
// clear auth token before refreshing it.
// call c.Auth.Authenticate with an invalid token will always fail the auth check on the server-side,
// if the server has not apply the patch of pr #12165 (https://github.com/etcd-io/etcd/pull/12165)
// and a rpctypes.ErrInvalidAuthToken will recursively call c.getToken until system run out of resource.
c.authTokenBundle.UpdateAuthToken("")
gterr := c.getToken(ctx)
if gterr != nil {
c.GetLogger().Warn(
"retrying of unary invoker failed to fetch new auth token",
zap.String("target", cc.Target()),
zap.Error(gterr),
)
return gterr // lastErr must be invalid auth token
}
continue
}
...
}
重试次数
此处Invoke的大循环里,默认callOpts.max是0,也就是说尝试一次Invoke后就会return错误
由于数据在栈内是单调递增或单调递减的,单调栈适合用来找出数组中第一个大于或小于某个元素的场景。元素出栈后,再根据题意对出栈元素进行处理,更新数据至result。
标准模板
- 第一个for循环内循环输入数组,
- 第二个for循环维持栈内单调特性,不满足单调的元素依次出栈
- 第一个for循环内对元素入栈
直接输入出栈元素即可
func nextGreaterElement(nums1 []int, nums2 []int) []int {
//单调递减栈
var stack,res []int
//标准模板,首个元素先入栈
stack = append(stack, 0)
//由于只需要输出num1的元素,构造nums1的map作为需要输出数据的查询
map1 := make(map[int]int)
for i,v := range(nums1) {
map1[v] = i
//顺便初始化res,查不到的为-1
res = append(res, -1)
}
for i:=1; i < len(nums2); i++ {
// 单调递减,所以>=的都出栈
for len(stack) > 0 && nums2[stack[len(stack)-1]] <= nums2[i] {
// 查表,需要输出的加入res
if idx, ok := map1[nums2[stack[len(stack)-1]]]; ok {
res[idx] = nums2[i]
}
//pop
stack = stack[:len(stack)-1]
}
// push
stack = append(stack, i)
}
return res
}
出栈后计算出栈元素高度所在层的面积
207. 课程表 - 力扣(LeetCode)
思路
课程之间的依赖关系可以用图来表示
- 顶点:课程
- 边:有向的边,起点是前置课程,终点是后置课程
这种图叫做AOV(Activity On Vertex)网络,字面意思就是边代表了节点之间的活动的先后关系。
按照题意,这个图是无环的(课程不能循环依赖),也就是DAG图。DAG图其实就是一颗树,只不过根节点是一个虚拟根节点(可以有多个起始根节点,但外面可以用一个虚拟根节点作为他们的父节点)。
因此,可以用广度优先遍历(BFS)来求解。队列存放可以选的课程(入度为0),依次出队列(选课)。直到队列为空(没有课可以选了),看是否已经学完所有的课程
- 入度:指向自己的边的数量,入度为0表示自己没有前置课程,可以入队列
- 出度:指向别人的边。用一个数据结构记录每个节点的出度列表。当某个节点出队列时,更新本节点的出度列表里所有节点的入度(-1)
代码
func canFinish(numCourses int, prerequisites [][]int) bool {
//保存各课程的入度 空间O(v)
indegree := make([]int, numCourses)
// 保存各课程的出度列表 空间O(e)
courseMp := make(map[int][]int)
//时间 O(e)
for _, pre := range(prerequisites) {
indegree[pre[0]]++
courseMp[pre[1]] = append(courseMp[pre[1]], pre[0])
}
var q []int
// 已经学习了的课程的计数
var num int
// 初始入度为0的课程加入队列
for course, depends := range(indegree) {
if depends == 0 {
q = append(q, course)
}
}
//循环直到队列为空 时间O(v)
for len(q) > 0 {
// 出队列
finished := q[0]
q = q[1:]
num++
// 更新入度数据结构(slice)
// 从出度课程列表中直接取受影响的课程
for _, course := range(courseMp[finished]) {
indegree[course]--
// 入度-1后若为0,则可以入队列
if indegree[course] == 0 {
q = append(q, course)
}
}
}
//是否学完
return num == numCourses
}
- 时间复杂度:O (v+e)
- 空间复杂度: O(v+e)
若需要省空间,不需要省时间,可以不使用courseMp存放出度数组,每次重新遍历prerequisites 获取出度数组。此时处理每个节点都需要重新遍历所有的边,因此:
870. 优势洗牌 - 力扣(LeetCode)
思路
- 将nums1(自己的马)进行升序排序,得到下等马->上等马的序列
- 贪心策略
- 若某个位置上自己的马比对手的马强,由于已经排过序了,已经是最下等的马了,因此使用这匹马
- 若某个位置上自己的马比对手的马弱,将该下等马放到最后的位置(对手的上等马的位置)
- 由于nums2的顺序固定(已知对手上场顺序),因此使用nums2的元素值对nums2的index进行排序,得到上场顺序(ids)
- 按照上场顺序(ids)依次写入ans数组中
代码
func advantageCount(nums1 []int, nums2 []int) []int {
sort.Ints(nums1)
n := len(nums1)
ans := make([]int, n)
ids := make([]int, n)
for i := 0; i < n; i++ {
ids[i] = i
}
sort.Slice(ids, func(i, j int) bool { return nums2[ids[i]] < nums2[ids[j]] })
left, right := 0, n-1
for _, v := range nums1 {
if v > nums2[ids[left]] {
ans[ids[left]] = v
left++
} else {
ans[ids[right]] = v
right--
}
}
return ans
}
总结
灵活运用不对数组进行真正的排序,而是获得排序后的index的顺序这一技巧
API Server

Controller

Device Plugin


Kube Proxy

Pod Create

Schduler(V1.13)

数据库切换
默认会创建16个数据库,客户端通过select选取。但一般情况只用第0个数据库,切换容易导致误操作
typedef struct redisDb {
dict *dict; //键空间
dict *expires; //过期字典
int id;
} redisDb;
所有键空间存储在redisDb的dict中,称为key space
每个键是字符串对象,值是各种对象
读写键操作
- 更新keyspace_hits和keyspace_misses,用来输出统计数据
- 更新键的LRU时间
- 若发现该键已经过期,则删除键
- 若该键被watch,标记键为dirty,使得监听者发现后重新拉数据
- dirty计数器++,用来触发持久化和复制操作
过期字典的键是键空间的键字符串对象的指针(不会新分配空间),值是longlong类型的过期时间(毫秒精度的unix时间戳)
判断是否过期:
先在过期字典里取key的过期时间,再与当前时间比较
删除策略
(redis同时采用惰性删除和定期删除策略,其中定期删除是随机取出一定数量的键做检查):
- 定时删除:过期时立刻删除(问题:要创建大量定时器,占用太多CPU,因此不合理)
- 惰性删除:获取键时若过期才删除 (问题:内存最不友好)
- 定期删除:定期对所有key进行检查并删除 (问题:如何确定定期时间,太快或太慢都不好)
持久化
解密Redis持久化 - justjavac - 博客园 (cnblogs.com)
rdb
记录键值
主服务器初始化加载时不会加载过期的键值,从服务器会加载过期的键值,但同步之后也会被清空掉
主节点统一管理过期删除,从节点只能被动接收del命令,保证了数据一致性,但从节点里可能会有过期键值
SAVE阻塞保存,BGSAVE用子进程保存
自动保存:自动保存规则设置在一个列表中,表示一段时间内进行了多少次改动就满足保存规则
每次写入会将db的dirty计数器加1,且每次保存会保存的时间戳lastsave。当距离lastsave的时间超过条件中设置的时间,比较dirty与规则中设置的改动次数,若满足则触发BGSAVE
RDB数据格式
| REDIS | db_version | database 0 | database 3 | EOF | check_sum |
|---|
| | | | | |
格式细节包括压缩算法略过
aof
记录写命令(启动时优先选择加载aof)
命令追加:按redis协议追加到aof_buf缓冲区中
文件写入和同步:redis server主线程每次循环结束前,将缓冲区写入aof文件,并调用fsync落盘
主从(复制)
同步
slave刚上线或断线重连时的第一次全量同步
slave的客户端主动发送sync命令,触发master的BGSAVE,BGSAVE过程中将命令存入缓冲区,BGSAVE完成后发送RDB文件,slave完成RDB载入后再发送缓冲区的指令
命令传播
完成同步后的增量同步
master主动发送命令
psync
优化后的sync,作为断线重连后的增量同步
slave发送psync命令,master返回+continue,之后发送断开期间执行的写命令
偏移量
主节点和从节点各自维护一个偏移量,表示当前已接收数据的字节数。当从节点发现自身偏移量与主节点不一致时,主动向主节点发送psync命令
复制缓冲区
主节点进行命令传播时(增量同步),会将写命令复制一份到缓冲区。且每个写命令都绑定一个对应的偏移量。从节点发送的psync中带有偏移量,
通过该偏移量在复制缓冲区中查找偏移量之后的写命令。如果查不到,则执行完整同步(sync)
服务器运行ID
从节点向主节点注册自己的分布式ID,新上线的从节点若不在注册表内,则进行完整同步(sync),否则进行部分重同步。
同步过程
slaveof命令设置redisServer中的masterhost和masterport字段,之后主从连接由cron定时器任务里触发
- anetTcpConnect建立一个新的tcp连接
- ping-pong命令测试连接
- auth鉴权
- 发送端口号,主节点刷新client信息
- psyn/sync 同步
- 命令传播
- 心跳 发送REPLCONF ACK命令,其中带有从节点的偏移量,可以检测命令丢失(命令丢失后主节点和从节点的偏移量会不一样);收到心跳的时间戳用来监测网络延迟状态,若一定数量的从服务器的lag超过一定值,表示该主从集合不健康,不允许client写入
一致性
不是强一致性(cap),是最终一致性。用最终一致性换取了高吞吐量
- master与slave的同步存在数据不一致的时间窗口期
- 网络分区后哨兵模式或者集群模式的选主会产生脑裂
哨兵
多了一个哨兵节点进行主节点选举,触发从同步等工作,数据的同步还是主从模式
哨兵节点运行的是一个特殊模式的redis服务器,里面没有数据库。
连接类型
命令连接
订阅连接
/*实例不是 Sentinel (主服务器或者从服务器)
并且以下条件的其中一个成立:
1)SENTINEL 未收到过这个服务器的 INFO 命令回复
2)距离上一次该实例回复 INFO 命令已经超过 info_period 间隔
那么向实例发送 INFO 命令
*/
if ((ri->flags & SRI_SENTINEL) == 0 &&
(ri->info_refresh == 0 ||
(now - ri->info_refresh) > info_period))
{
/* Send INFO to masters and slaves, not sentinels. */
retval = redisAsyncCommand(ri->cc,
sentinelInfoReplyCallback, NULL, "INFO");
if (retval == REDIS_OK) ri->pending_commands++;
} else if ((now - ri->last_pong_time) > ping_period) {
/* Send PING to all the three kinds of instances. */
sentinelSendPing(ri);
} else if ((now - ri->last_pub_time) > SENTINEL_PUBLISH_PERIOD) {
/* PUBLISH hello messages to all the three kinds of instances. */
sentinelSendHello(ri);
}
节点的连接
哨兵主定时任务开始时,以1s或10s的间隔发送INFO命令,得到主节点的回复,并处理INFO回复的信息。回复中包含该主节点的从节点ip+port。处理函数中更新主节点的实例sentinelRedisInstance,并创建从节点,进行从节点的连接,获取从节点的详细信息。
此系列作为redis设计与实现的笔记,会将本人自认为重点部分单独拎出来,并加入本人的一些理解。
SDS
(simple dynamic string)
等同于go里的slice
struct sdshdr {
int len;
int free;
char buf[];
}
优点:
- 杜绝缓冲区溢出(free检验)
- 减少修改字符串时的内存分配次数(策略:小于1MB时,len=free,大于1MB时,free=1MB)
- 惰性空间释放(删除时实际空间并未缩减)
- 二进制安全(C字符串视/0为结束,不能用来存带/0的二进制数据)
- 部分兼容C字符串函数(默认在char数组最后加入/0,来兼容C字符串函数)
链表
双向链表,无环,保存头指针和尾指针,保存链表长度字段,链表节点的数据为void*指针
字典
字典有type,每个type实现了一系列操作kv的函数(对比,生成哈希,删除,复制等)
每个字典存有两个哈希表,一般用第一个ht[0],第二个ht[1]用作rehash时的暂存容器
哈希表由数组实现,数组存放kv链表头节点,链地址法解决冲突,冲突的新键值往表头加(由于没有指向表尾的指针)
rehash标志位,当没有进行rehash时为-1
key–>(hashfunc)–>hash–>(hashmask)–>index
murmurhash算法:输入有规律情况还是能生成随机分布性的hash
rehash
为ht[1]哈希表分配空间,空间的大小取决于当前ht[0]包含的键值数量以及要进行的操作,重新计算所有键值在ht[1]的索引并插入,插入后将ht[1]设置为ht[0],并ht[1]指向新创的空白hash表
负载因子=ht[0].used/ht[0].size
何时进行扩展?
在进行持久化操作时(BGSAVE,BGREWRITEAOF),负载因子>=5,普通场景下负载因子>=1
何时进行收缩?
负载因子<0.1
渐进式rehash
开始时rehashidx为0,表示正在进行rehash,rehash期间对字典的CRUD会顺带将ht[0]上的KV rehash到ht[1],完成后rehashidx置为-1,表示已经完成。rehash期间的CRUD会先在ht[0]上查,查不到再去ht[1]查
跳表
用来实现有序集合键,用作集群节点内部数据结构
优点,相较于平衡树,实现简单,且rebalance的效率高(局部rebalance,只修改搜索路径上的节点)
链表的扩展,维护了多个指向其他节点的指针,类似二分查找
每个节点的层数是随机生成的,遍历时先走最上层的前进指针,若下一条节点的分值比要查找的分值高,则通过回退指针回到原来的节点并走下一层的前进指针,以此类推
前进指针中存有跨度,累加所有跨度,当找到该节点后作为该节点在跳表中的排位(数组的index)
比较分值时,分值可能相同,相同时比较value值(obj指向的sds的字典序)
节点更新时,若score的改变未影响排序,则查找并直接改score,否则进行先删除后插入操作,会进行两次路径搜索
整数集合
底层保存的整数为byte数组(int8),按照解码类型(encoding)存入int16,int32或int64的数据
只能存一种类型的数据,短int集合中插入长int后,往长int类型兼容(升级)
节约内存,int16不需要分配int64的空间
自适应灵活性,集合中添加长度更长的新元素,会自动升级,但不支持降级
压缩列表
为了节约内存,将键值为小整数值和短字符串的entry按照特殊编排压缩为一段内存块
先略过
对象
创建键值对时,键和值都被封装成对象,并指明对象的类型,编码以及底层数据结构的指针
key总是字符串对象,value可以是字符串对象,列表对象,哈希对象,集合对象,有序集合对象(zset)
编码指定了底层数据结构, 每种对象类型有多种编码的实现
字符串对象
long:value是数字,可以用long存
raw:value是字符串,长度大于32byte,用sds存,sds的内存是另外一块,和redisObject不连续
embstr:value是字符串,长度小于32byte,用sds存,sds的内存与redisObject的内存连续 (好处:减少分配和释放内存的次数,增加缓存命中率;坏处:没有实现写方法,只读,修改的话需要先转raw)
编译过程
安装llvm-10,clang-10
apt-install llvm-10 clang-10
下载bpf2go
go install github.com/cilium/ebpf/cmd/bpf2go@latest
修改bpf程序的include
GOPACKAGE=main bpf2go -cc clang-10 -cflags '-O2 -g -Wall -Werror' -target bpfel,bpfeb bpf helloworld.bpf.c -- -I /root/ebpf/examples/headers
得到大端和小端两个版本的ELF文件,之后在go程序里加载即可。cpu一般都是小端。
内核版本要求
经测试一些gobpf的一些syscall不适配较低版本的内核(例如5.8的BPF_LINK_CREATE会报参数错误),建议使用最新版本内核5.19
bpf_map
用户态程序首先加载bpf maps,再将bpf maps绑定到fd上。elf文件中的realocation table用来将代码中的bpf maps重定向至正确的fd上,用户程序在fd上发起bpf syscall
map的value尽量不要存复合数据结构,若bpf程序和用户态程序共用一个头文件,用户态程序调用bpf.Lookup时由于结构体变量unexported而反射失败
pinning object
将map挂载到/sys/fs/bpf
ebpf.CollectionOptions{
Maps: ebpf.MapOptions{
// Pin the map to the BPF filesystem and configure the
// library to automatically re-write it in the BPF
// program so it can be re-used if it already exists or
// create it if not
PinPath: pinPath
其他用户态程序获取pinned map的fd
摘自
eBPF 用户空间虚拟机实现相关 | Blog (forsworns.github.io)
[
译] Cilium:BPF 和 XDP 参考指南(2021) (arthurchiao.art)
hook point
可以插入bpf代码的位置
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
};
程序类型
| bpf_prog_type | BPF prog 入口参数(R1) | 程序类型 |
|---|
| BPF_PROG_TYPE_SOCKET_FILTER | struct __sk_buff | 用于过滤进出口网络报文,功能上和 cBPF 类似。 |
| BPF_PROG_TYPE_KPROBE | struct pt_regs | 用于 kprobe 功能的 BPF 代码。 |
| BPF_PROG_TYPE_TRACEPOINT | 这类 BPF 的参数比较特殊,根据 tracepoint 位置的不同而不同。 | 用于在各个 tracepoint 节点运行。 |
| BPF_PROG_TYPE_XDP | struct xdp_md | 用于控制 XDP(eXtreme Data Path)的 BPF 代码。 |
| BPF_PROG_TYPE_PERF_EVENT | struct bpf_perf_event_data | 用于定义 perf event 发生时回调的 BPF 代码。 |
| BPF_PROG_TYPE_CGROUP_SKB | struct __sk_buff | 用于在 network cgroup 中运行的 BPF 代码。功能上和 Socket_Filter 近似。具体用法可以参考范例 test_cgrp2_attach。 |
| BPF_PROG_TYPE_CGROUP_SOCK | struct bpf_sock | 另一个用于在 network cgroup 中运行的 BPF 代码,范例 test_cgrp2_sock2 中就展示了一个利用 BPF 来控制 host 和 netns 间通信的例子。 |
BPF 程序类型就是由 BPF side 的代码的函数参数确定的,比如写了一个函数,参数是 struct __sk_buff 类型的,它就是一个 BPF_PROG_TYPE_SOCKET_FILTER 类型的 BPF 程序