lpm有多种实现方式,最常用的是用trie。当然也会有更简单的实现方式,例如某些特定场景用多重哈希表就能解决(ipv4地址,32个掩码对应32个哈希表)
从4.11内核版本开始,bpf map引入了BPF_MAP_TYPE_LPM_TRIE
主要是用于匹配ip地址,内部是将数据存储在一个不平衡的trie中,key使用prefixlen,data
data是以大端网络序存储的,data[0]存的是msb。
prefixlen支持8的整数倍,最高可以是2048。因此除了ip匹配,还可以用来做端口,协议,vpcid等等的扩充匹配。在应用层面上除了做路由表,还可以作为acl,policy等匹配过滤的底层实现
使用方式
BPF_MAP_TYPE_LPM_TRIE — The Linux Kernel documentation
除了上述基本的Ipv4的使用方式,扩展使用方式可以参考一下cillium中IPCACHE_MAP的使用
首先是map的定义
struct ipcache_key {
struct bpf_lpm_trie_key lpm_key;
__u16 cluster_id;
__u8 pad1;
__u8 family;
union {
struct {
__u32 ip4;
__u32 pad4;
__u32 pad5;
__u32 pad6;
};
union v6addr ip6;
};
} __packed;
/* Global IP -> Identity map for applying egress label-based policy */
struct {
__uint(type, BPF_MAP_TYPE_LPM_TRIE);
__type(key, struct ipcache_key);
__type(value, struct remote_endpoint_info);
__uint(pinning, LIBBPF_PIN_BY_NAME);
__uint(max_entries, IPCACHE_MAP_SIZE);
__uint(map_flags, BPF_F_NO_PREALLOC);
} IPCACHE_MAP __section_maps_btf;
可以看到cillium将v4和v6合并成一个map查询,匹配条件并带上了cluster_id
hook点
大部分是挂载位置是tc,tc是网络协议栈初始处理挂载点
// linux source code: dev.c
__netif_receive_skb_core
| list_for_each_entry_rcu(ptype, &ptype_all, list) {...} // packet capture
| do_xdp_generic // handle generic xdp
| sch_handle_ingress // tc ingress
| tcf_classify
| __tcf_classify // ebpf program is working here
如果没有下发policy,xdp就不会挂载各类filter程序
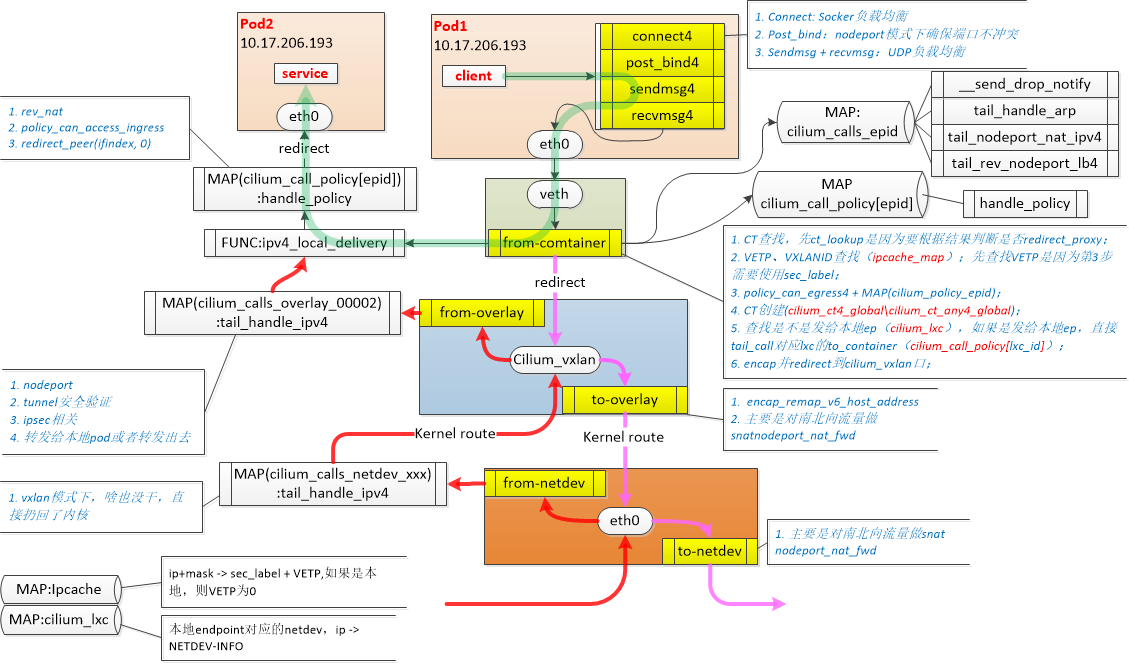
网络设备
cillium的网络方案不像常规的网桥模式(ovs,linux bridge),datapath不是一个完整的run to completion,而是分散在各个虚拟接口上,类似pipeline模式
cillium_host: 集群内所有podCIDR的网关,地址对容器可见
cilium_net: cilium_host的veth对,ipvlan模式才会用到?
clilium_vxlan: 用来提供Pod跨节点通信overlay封装
lxcXXXX: 容器veth对在主机侧的接口
同节点pod2pod
cillium_host是所有pod的网关,因此会先arp request该地址。arp相应其实是在lxc处被代答了,arp报文不会走到cillium_host
// bpf_lxc.c
__section_entry
int cil_from_container(struct __ctx_buff *ctx)
{
...
case bpf_htons(ETH_P_ARP):
ret = tail_call_internal(ctx, CILIUM_CALL_ARP, &ext_err);
break;
...
}
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_ARP)
int tail_handle_arp(struct __ctx_buff *ctx)
{
union macaddr mac = THIS_INTERFACE_MAC;
union macaddr smac;
__be32 sip;
__be32 tip;
/* Pass any unknown ARP requests to the Linux stack */
if (!arp_validate(ctx, &mac, &smac, &sip, &tip))
return CTX_ACT_OK;
/*
* The endpoint is expected to make ARP requests for its gateway IP.
* Most of the time, the gateway IP configured on the endpoint is
* IPV4_GATEWAY but it may not be the case if after cilium agent reload
* a different gateway is chosen. In such a case, existing endpoints
* will have an old gateway configured. Since we don't know the IP of
* previous gateways, we answer requests for all IPs with the exception
* of the LXC IP (to avoid specific problems, like IP duplicate address
* detection checks that might run within the container).
*/
if (tip == LXC_IPV4)
return CTX_ACT_OK;
return arp_respond(ctx, &mac, tip, &smac, sip, 0);
}
普通ipv4报文,走handle_ipv4_from_lxc
原生的ipvs仅处理三种类型的ICMP报文:ICMP_DEST_UNREACH、ICMP_SOURCE_QUENCH和ICMP_TIME_EXCEEDED
对于不是这三种类型的ICMP,则设置为不相关联(related)的ICMP,返回NF_ACCEPT,之后走本机路由流程
dpvs对ipvs进行了一些修改,修改后逻辑如下
icmp差错报文流程
__dp_vs_in
__dp_vs_in_icmp4 (处理icmp差错报文,入参related表示找到了关联的conn)
若不是ICMP_DEST_UNREACH,ICMP_SOURCE_QUENCH,ICMP_TIME_EXCEEDED,返回到_dp_vs_in走普通conn命中流程
icmp差错报文,需要将报文头偏移到icmp头内部的ip头,根据内部ip头查找内部ip的conn。
若找到conn,表明此ICMP报文是由之前客户端的请求报文所触发的,由真实服务器回复的ICMP报文。将related置1
若未找到则返回accept,返回到_dp_vs_in走普通conn命中流程
找net和local路由,之后走__dp_vs_xmit_icmp4
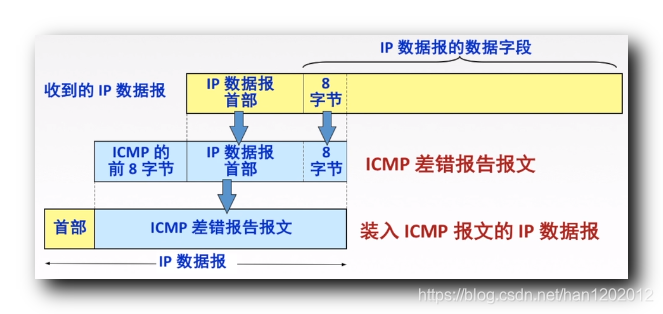
数据区的前8个字节恰好覆盖了TCP报文或UDP报文中的端口号字段(前四个字节)
inbound方向根据内部ip的conn修改数据区目的端口为conn->dport,源端口改为conn->localport,
outbound方向将目的端口改为conn->cport,源端口改为conn->vport
client (cport ) <–> (vport)lb(lport) <–> rs(dport)
重新计算icmp头的checksum,走ipv4_output
实际应用上的问题
某个rs突然下线,导致有时访问vip轮询到了不可达的rs,rs侧的网关发送了一个dest_unreach的icmp包
该rs的conn还未老化,__dp_vs_in_icmp4流程根据这个icmp的内部差错ip头找到了还未老化的conn,将icmp数据区的port进行修改发回给client
但是一般情况,rs下线后,该rs的conn会老化消失,内层conn未命中,还是走外层icmp的conn命中流程转给client。这样内部数据区的端口信息是错的(dport->lport,正确情况是vport->cport)
非差错报文流程
返回_dp_vs_in走普通conn命中流程
原本dp_vs_conn_new流程中,先查找svc。icmp的svc默认使用端口0进行查找。但是ipvsadm命令却对端口0的service添加做了限制,导致无法添加这类svc。
svc = dp_vs_service_lookup(iph->af, iph->proto, &iph->daddr, 0, 0, mbuf, NULL, &outwall, rte_lcore_id());
若未查到走INET_ACCEPT(也就是继续往下进行走到ipv4_output_fin2查到local路由,若使用dpip addr配上了vip或lip地址,则会触发本地代答)。
若查到svc,则进行conn的schedule,之后会走dp_vs_laddr_bind,但是dp_vs_laddr_bind不支持icmp协议(可以整改),最终导致svc可以查到但是conn无法建立,最后走INET_DROP。
概括一下:
- 未命中svc,走后续local route,最终本地代答
- 命中svc后若conn无法建立,drop
- 命中svc且建立conn,发往rs或client
icmp的conn
_ports[0] = icmp4_id(ich);
_ports[1] = ich->type << 8 | ich->code;
Inbound hash和outboundhash的五元组都使用上述这两个port进行哈希,并与conn进行关联。
具体的laddr和lport保存在conn里面。其中只用到laddr做l3的fullnat。由于icmp协议没有定义proto->fnat_in_handler,因此fnat时,从sa_pool分配到的lport对于icmp来说没有用。
试想ping request和ping reply场景:
由于request和reply的ich->type不一样,outboundhash必定不命中(且fnat流程中的laddr_bind还会修改一次outboundhashtuple的dport,修改成sapool分配的port,因此也不会命中outbound hash)。
一次来回的ping会创建两个conn,且都只命中inboundhash。
个人认为比较合理的方案
ipvsadm
放通port=0的svc的创建,用户需要fwd icmp to rs时,需要添加icmp类型的svc。否则icmp会被vip或者lip代答,不会透传到rs或client
icmp差错报文
保持原状,对找不到关联的conn连接的差错报文进行drop。
ipv4_rcv_fin 是路由转发逻辑, INET_HOOKPRE_ROUTING 中走完hook逻辑后,根据dpvs返回值走ipv4_rcv_fin
路由表结构体
struct route_entry {
uint8_t netmask;
short metric;
uint32_t flag;
unsigned long mtu;
struct list_head list;
struct in_addr dest; //cf->dst.in
struct in_addr gw;// 下一跳地址,0说明是直连路由,下一跳地址就是报文自己的目的地址,对应配置的cf->via.in
struct in_addr src; // cf->src.in, 源地址策略路由匹配
struct netif_port *port; // 出接口
rte_atomic32_t refcnt;
};
路由类型
/* dpvs defined. */
#define RTF_FORWARD 0x0400
#define RTF_LOCALIN 0x0800
#define RTF_DEFAULT 0x1000
#define RTF_KNI 0X2000
#define RTF_OUTWALL 0x4000
路由表类型
#define this_route_lcore (RTE_PER_LCORE(route_lcore))
#define this_local_route_table (this_route_lcore.local_route_table)
#define this_net_route_table (this_route_lcore.net_route_table)
#define this_gfw_route_table (this_route_lcore.gfw_route_table)
#define this_num_routes (RTE_PER_LCORE(num_routes))
#define this_num_out_routes (RTE_PER_LCORE(num_out_routes))
local 类型路由的作用和 Linux 下的 local 路由表的功能基本一样,主要是记录本地的 IP 地址。
我们知道进入的数据包,过了 prerouting 后是需要经过路由查找,如果确定是本地路由(本地 IP)就会进入 LocalIn 位置,否则丢弃或进入 Forward。
总体架构
lb session同步采用分布式架构,session创建流程触发session数据发送,依次向集群内所有其他节点发送
其他节点收到新的session数据修改本地session表。
session接收和发送各占一个独立线程。
step1: 向所有其他节点发送session数据
remote session:从别的节点同步来的session
local session:本节点收到数据包自己生成的session
step2: session同步至worker
方案一(有锁):
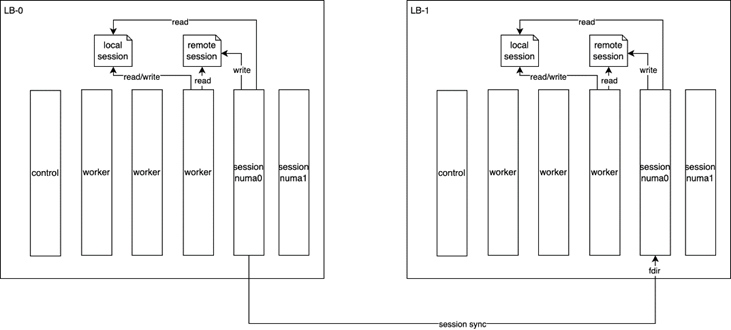
• 独立进程和core处理session同步(per numa)
• 每个lcore分配local session和remote session,正常情况下都能直接从local session走掉
• 同步过来的session写到remote session表
• session ip根据fdir走到指定进程
方案二(无锁):
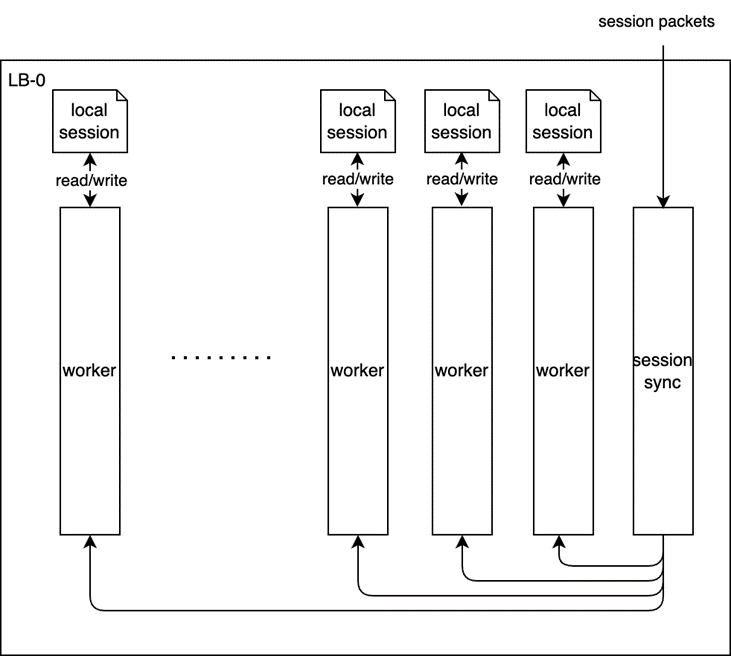 • 独立进程和core处理session同步消息
• 每个lcore 有来local session和remote session,通过owner属性区分。
• 同步过来的session由session_sync core发消息给对应的slave,由对应的slave进行读写,因此可以做到无锁。
• session ip根据fdir走到指定core
• 独立进程和core处理session同步消息
• 每个lcore 有来local session和remote session,通过owner属性区分。
• 同步过来的session由session_sync core发消息给对应的slave,由对应的slave进行读写,因此可以做到无锁。
• session ip根据fdir走到指定core
session同步具体实现
亟待解决的问题:
同步过来的session什么时候老化?
别的节点上线,本节点要发送哪些session?
别的节点下线,本节点要删除哪些session?
是否要响应下线节点的删除/老化请求?
下线节点怎么知道自己已经下线(数据面)?
解决方案:
方案一: session增加owner属性c
owner属性:
conn.owner // indicates who has this session
session 同步状态转移图
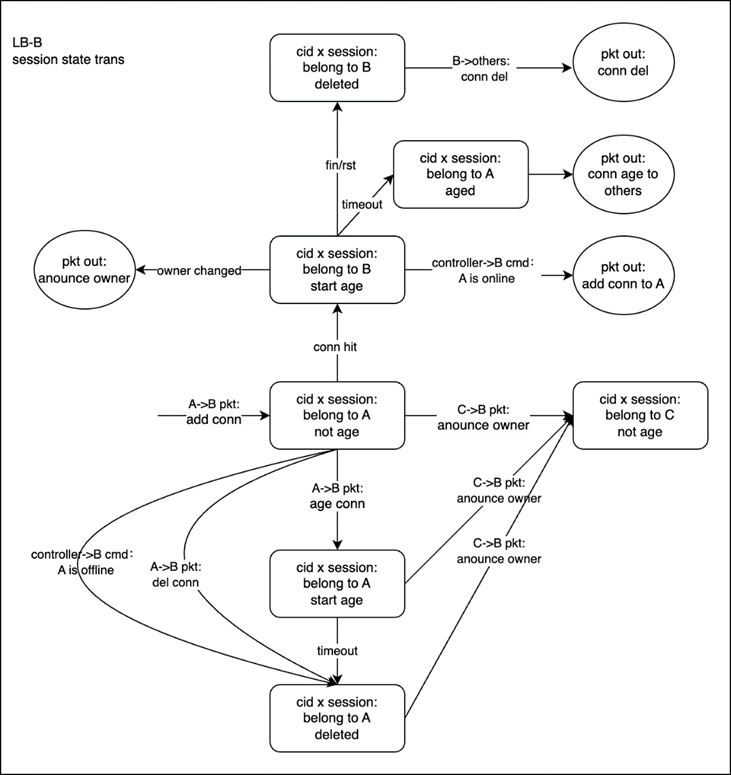
一条session在一个集群中,应当只有一台机器在使用,所以有一个owner属性,代表这条session被谁拥有,其它所有机器只对这条session的owner发起的增删改查请求做响应。
同步动作
session同步应当时实时的。在以下场景被触发:
新建session
发送方:
session新建完成之后:对于tcp,是握手完毕的;对于udp,是第一条连接。
接收方:
接收来自发送方的session,在对应core上新建这条连接,开启老化,老化时间设定为默认时间(1小时)。
fin/rst
发送方:
发送删除session消息
接收方:
接收方接收session,做完校验后在对应core上删除session
老化
发送方:
老化时间超时之后,本地session删除,同时发布老化信息,告知其它lb,
接收方:
其它lb 做完校验后,开始老化这条session。
设备下线
下线后通过控制器更新其他lb的session同步地址信息,不再向该设备同步,同时开始老化全部属于该设备的session。
设备上线(包含设备扩容)
新设备:
新上线设备引流前要接收其他设备的存量session信息,这个功能通过控制器触发完成,控制器感知到新lb上线后通知集群内其他lb向它同步存量session,session数量达到一致时(阿里gw用70%阈值)允许新lb引流。
旧设备:
向目的方发送全部的属于自己的session。
dpvs ingress流程分析
从 lcore_job_recv_fwd 开始,这个是dpvs收取报文的开始
设备层
dev->flag & NETIF_PORT_FLAG_FORWARD2KNI —> 则拷贝一份mbuf到kni队列中,这个由命令行和配置文件决定(做流量镜像,用于抓包)
eth层
netif_rcv_mbuf 这里面涉及到vlan的部分不做过多解析
不支持的协议
目前dpvs支持的协议为ipv4, ipv6, arp。 其它报文类型直接丢给内核。其他类型可以看
eth_types。
to_kni
RTE_ARP_OP_REPLY
复制 nworks-1 份mbuf,发送到其它worker的arp_ring上 ( to_other_worker ), 这份报文fwd到
arp协议.
RTE_ARP_OP_REQUEST
这份报文fwd到
arp协议.
arp协议
ip层
- ipv4协议 (ipv6数据流程上一致)
ipv4_rcv
ETH_PKT_OTHERHOST
报文的dmac不是自己,
drop
ipv4 协议校验
不通过,
drop
下一层协议为 IPPROTO_OSPF
to_kni
INET_HOOK_PRE_ROUTING hook
hook_list: dp_vs_in , dp_vs_prerouting
这两个都与synproxy有关系,但是我们不会启用这个代理,不过需要注意的是syncproxy不通过时会丢包
drop
dp_vs_in
非 ETH_PKT_HOST(broadcast 或者 multicast报文)或ip报文交给 ipv4_rcv_fin 处理
非 udp, tcp, icmp, icmp6报文交给 ipv4_rcv_fin 处理
linux的RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景。
dpdk中由于writer和reader同时访问一段内存,删除元素的时候需要确保
- 删除时不会将内存put回allocator,而是删掉这段内存的引用。这样确保了新的访问者不会拿到这个元素的引用,而老的访问者不会在访问过程中core掉
- 只有在元素没有任何引用计数时,才释放掉该元素的内存
静默期是指线程没有持有共享内存的引用的时期,也就是下图绿色的时期

上图中,有三个read thread,T1, T2,T3。两条黑色竖线分别代表writer执行delete和free的时刻。
执行delete时,T1和T2还拿着entry1和entry2的reference,此时writer还不能free entry1或entry2的内存,只能删除元素的引用.
writer必须等到执行delete时,当时引用该元素的的线程,都完成了一个静默期之后,才可以free这个内存。
writer不需要等T3进入静默期,因为执行delete时,T3还在静默期。
如何实现RCU机制
- writer需要一直轮询reader的状态,看是否进入静默期。这样会导致一直循环轮询,造成额外的cpu消耗。由于需要等reader的静默期结束,reader的静默期越长,reader的数量越多,writer cpu的消耗会越大,因此我们需要短的grace period。但是如果将reader的critical section减小,虽然writer的轮询变快了,但是reader的报告次数增加,reader的cpu消耗会增加,因此我们需要长的critical section。这两者之间看似矛盾。
- 长的critical section:dpdk的lcore一般都是一个while循环。循环的开始和结束必定是静默期。循环的过程中肯定是在访问各种各样的共享内存。因此critical section的粒度可以不要很细,不要每次访问的时候退出静默期,不访问的时候进入静默期,而是将整个循环认为是critical section,只有在循环的开始退出静默期,循环的结束进入静默期。
- 短的grace period:如果是pipeline模型,并不是所有worker都会使用相同的数据结构。话句话说,同一个元素,只会被部分的worker所引用和读取。因此writer不需要等到所有worker的critical section结束,而是使用该元素的worker结束critical section。这样将grace period粒度变小之后,缩短了writer整体的grace period。这种粒度的控制是通过 qsbr 实现的
如何使用rcu库
dpdk-stable-20.11.1/app/test/test_rcu_qsbr.c test_rcu_qsbr_sw_sv_3qs
先创建出struct rte_rcu_qsbr
sz = rte_rcu_qsbr_get_memsize(RTE_MAX_LCORE);
rv = (struct rte_rcu_qsbr *)rte_zmalloc(NULL, sz, RTE_CACHE_LINE_SIZE);
再初始化QS variable
rte_rcu_qsbr_init(rv, RTE_MAX_LCORE);
Reader注册自己的线程号,并上线(将自己加到writer的轮询队列里面)
online时会原子读qsbr里的token,并设置到v->qsbr_cnt[thread_id].cnt中
(void)rte_rcu_qsbr_thread_register(rv, lcore_id);
rte_rcu_qsbr_thread_online(rv, lcore_id);
每次读取共享数据后,更新自己的静默状态(rte_rcu_qsbr_quiescent)
do {
for (i = 0; i < num_keys; i += j) {
for (j = 0; j < QSBR_REPORTING_INTERVAL; j++)
rte_hash_lookup(tbl_rwc_test_param.h,
keys + i + j);
/* Update quiescent state counter */
rte_rcu_qsbr_quiescent(rv, lcore_id);
}
} while (!writer_done);
rte_rcu_qsbr_quiescent 是将qsbr->token更新到自己thread的token里去v->qsbr_cnt[thread_id].cnt
contiv memif
contiv的cni与device plugin相结合,实现了:
- Pod能同时接入不止一张网卡
- Pod接入的网卡可以是tap,veth,memif
devicePlugin
Device Plugin实际是一个运行在Kubelet所在的Node上的gRPC server,通过Unix Socket、基于以下(简化的)API来和Kubelet的gRPC server通信,并维护对应设备资源在当前Node上的注册、发现、分配、卸载。
其中,ListAndWatch()负责对应设备资源的discovery和watch;Allocate()负责设备资源的分配。
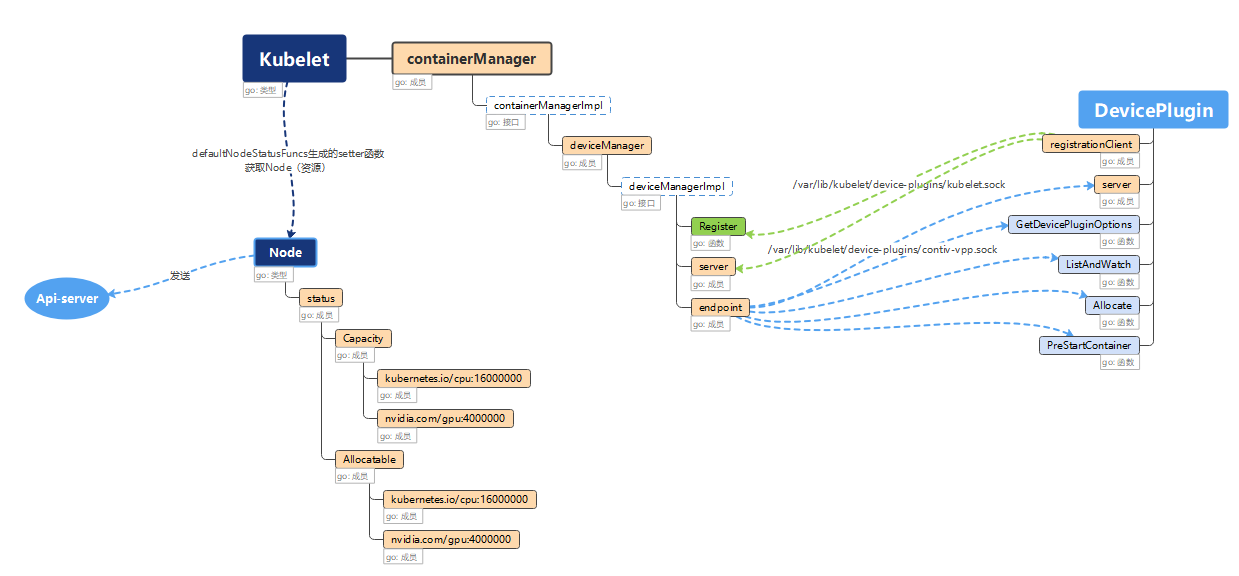
Insight
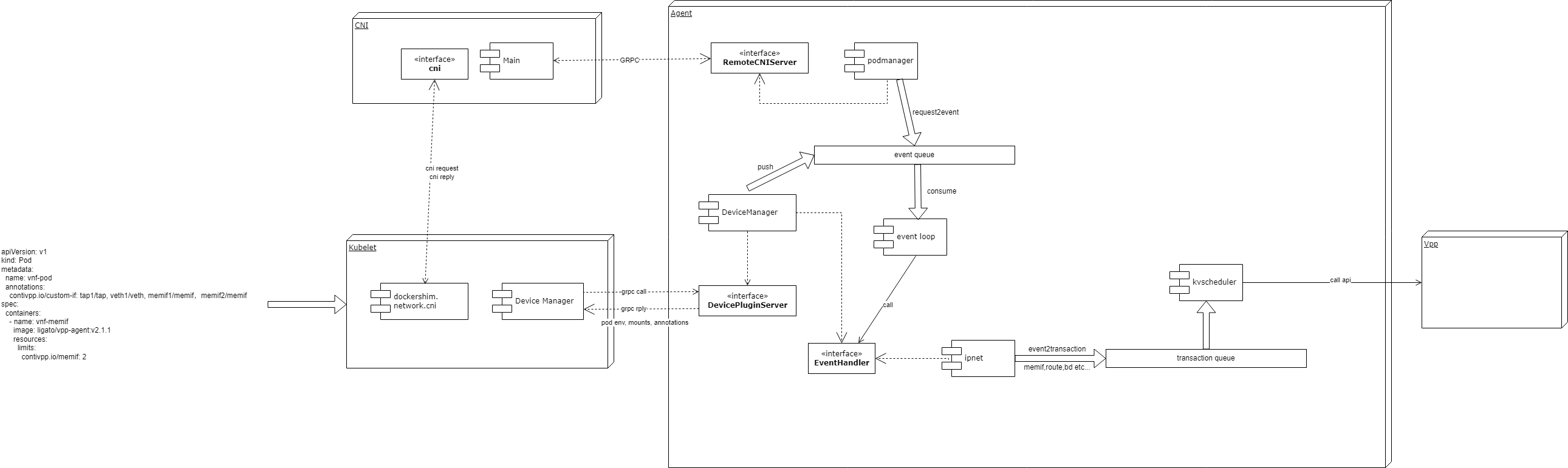
kubelet
kubelet接收上图格式的API。API中的annotations定义了pod的网卡个数与类型,resources中定义了所需要的device plugin的资源,也就是memif。
kubelet执行常规的syncPod流程,调用contiv cni创建网络。此时会在请求中将annotation传递给cni。
同时,agent的DevicePluginServer会向kubelet注册rpc服务,注册contivpp.io/memif的设备资源,从而kubelet的device manager会grpc请求DevicePluginServer获取contivpp.io/memif设备资源。
cni
cni实现了github.com/containernetworking/cni标准的add和del接口。实际上做的事情只是将cni请求转换为了对agent的grpc请求:解析args,并通过grpc调用agent的接口发送cniRequest,再根据grpc的返回结果,将结果再次转换成标准cni接口的返回格式
Agent
podmanager
podmanager实现了上述cni调用的grpc server,主要任务是将cni的request转换为内部的event数据格式,供event loop处理。
request是cni定义的请求数据类型,详见https://github.com/containernetworking/cni/blob/master/SPEC.md#parameters
event则是agent内部的关于pod事务模型,类似原生kvScheduler的针对vpp api的transaction。每一种event都会对应一个plugin去实现他的handler,供event loop调用。
event loop
event loop是整个contiv agent的核心处理逻辑,北向对接event queue,南向调用各个EventHandler,将event转换为kvScheduler的事务。
执行了以下步骤:
- 对事件的预处理,包括校验,判断事件类型,加载必要的配置等
- 判断是否是更新的事件
- 对事件的handler进行排序,并生成正向或回退的handler顺序
- 与本次事件无关的handler过滤掉
- 创建对这次事件的记录record
- 打印上述步骤生成的所有事件相关信息
- 执行事件更新或同步,生成vpp-agent里的事务
- 将contiv生成的配置与外部配置进行merge,得到最终配置
- 将最终配置的vpp-agent事务commit到agent的kvscheduler
- 若事务失败,将已经完成的操作进行回退
- 完成事件,输出记录record与计时
- 打印回退失败等不可恢复的异常
- 若开启一致性检查,则最好再执行一次同步校验
devicemanager
devicemanager既实现了对接kublet的DevicePluginServer,又实现了AllocateDevice类型的event的handler。换句话说是自己产生并处理自己的event。
主要业务逻辑:
创建memif socket文件的目录并挂载至容器
创建连接socket的secret。
上述的创建并不是真实的创建,而是把需要的信息(event.Envs, event.Annotations, event.Mounts)通过grpc返回给kublet,让kubelet去创建。
devicemanager还会将上述memif的信息保存在缓存中,供其他插件来获取。若缓存中信息不存在,则会调用kubelet的api获取信息。
ipNet
ipNet插件主要负责node和pod中各类网卡的创建销毁,vxlan的分配,vrf的分配等
更新网卡时,ipnet会读取annotation中kv,判断网卡类型。若类型为memif,则会向deviceManager获取当前pod里各容器的memifInfo,之后根据memifInfo里的socket地址和secret,创建memif类型的网卡事务,并 push 至kvscheduler
题目特征
要求统计满足一定条件的数的数量(即,最终目的为计数,若要结果则只能回溯爆搜得到);
这些条件经过转化后可以使用「数位」的思想去理解和判断;
输入会提供一个数字区间(有时也只提供上界)来作为统计的限制;
上界很大(比如 10^{18}),暴力枚举验证会超时。
思路
从高到低枚举每一位,统计符合target的个数,并记录到dp数组中。枚举完毕之后则得到答案。
因此数位dp的第一个状态都是数位的位置,第二个状态由题意来定
模板
以leetcode1012为例,统计小于等于n的数字中每一位的数字至少重复一次的个数。
模板时灵神的模板。难点主要是mask,isLimit,isNum这几个标识
- mask即dp的第二个状态,这边用到了状态压缩的思想,将0到9选过的状态压缩成一个数字(否则要10个状态)
- isLimit 标识了本次(i)选择的范围,是否受到n的影响。如果不引进这个变量,则需要考虑当前数字的最高位来决定本次的范围(最高位==n的最高位时,本次的范围是[0,s[i]],最高位<n的最高位时,本次的范围是[0,9])。可以发现这个限制是有传递的性质的,因此引入这个变量能简化范围的选择过程。
- isNum 标识了本次(i)之前是否有数字,换句话说本次(i)是否是第一个数字(最高位)。这个标识主要是解决前导0的问题,否则答案里会重复(前导两个0和前导三个0虽然是同个数字,但都会被记入答案)
func numDupDigitsAtMostN(n int) (ans int) {
s := strconv.Itoa(n) // s[0]是最高位
/* 若需要从低到高的顺序,则按如下生成
for ; n > 0; n = n / 10 {
list = append(list, n%10)
}
*/
m := len(s)
dp := make([][1 << 10]int, m)
// 数位dp的第一个状态都是数位的位置,第二个状态由题意来定
// 问题转换为计算没有重复数字的个数,因此第二个状态记录已经选过数字的集合
// i 表示从高到低第i位, j是前面已经选过的数字的集合,最大为[0,9]的子集个数
// 例如集合 {0,2,3} 对应的二进制数为 1101 (集合的思想就是状压)
for i := range dp {
for j := range dp[i] {
dp[i][j] = -1 // -1 表示没有计算过
}
}
var f func(int, int, bool, bool) int
// mask是dp数组中第二个状态
// isLimit表示当前是否受到n的约束,若为true表示当前位最大填s[i]
// 若isLimit为true时填了s[i],则isLimit为true传递到下一位,下一位也受到n的约束
// isNum主要是处理前导零的问题。isNum表示i前面是否填了数字
// 若isNum为true,则i位可以从0开始填;否则,说明i是第一位,i可以不填,或者至少填1(因为不能有前导0)
f = func(i, mask int, isLimit, isNum bool) (res int) {
if i == m { // base case,遍历完毕
if isNum { // 且不是全部跳过不选的
return 1 // 得到了一个合法数字
}
return
}
if !isLimit && isNum {
dv := &dp[i][mask]
if *dv >= 0 {
return *dv // dp匹配直接返回
}
defer func() { *dv = res }() // 未匹配到,则在return之后更新dp数组
}
if !isNum { // 可以跳过当前数位
res += f(i+1, mask, false, false)
}
d := 0
if !isNum {
d = 1 // 如果前面没有填数字,必须从 1 开始(因为不能有前导零)
}
up := 9
if isLimit {
up = int(s[i] - '0') // 如果前面填的数字都和 n 的一样,那么这一位至多填数字 s[i](否则就超过 n 啦)
}
for ; d <= up; d++ { // 枚举要填入的数字 d
if mask>>d&1 == 0 { // d 不在 mask 中
res += f(i+1, mask|1<<d, isLimit && d == up, true) // d写入mask, isLimit传递
} // 否则该分支的结果为0
}
return
}
return n - f(0, 0, true, false)
}
图解
Raft (thesecretlivesofdata.com)
算法目的:实现了分布式节点的数据一致性
节点有三个状态:follower,candidate,leader
leader election
初始阶段所有节点处于follower状态
follower状态下节点存在一个election timeout(150ms—300ms之间的随机数,随机降低了多个节点同时升级为candidate的可能性),election timeout内没有收到leader的heartbeat后,会自动升级为candidate状态,并开始一个新的election term。term是全局的,表示整个集群发生过选举的轮次(任期)。
candidate状态下,节点会向集群内所有节点发送requests votes请求。其他节点收到requests votes请求后,如果在本次term内还没有投过票,则会返回选票,如果candidate收到的选票占集群节点的大多数,则升级为本次term的leader节点。升级为leader之后向他的follower 发送append entries消息(也就是包含entry消息的心跳),follower也会返回消息的response,系统正常情况下维持在该状态
如果选举时,在一个term内发生了两个节点有同样的选票,会在超时过后进入下一轮进行重新选举
log replication
client的请求只会发往leader。leader收到改动后,将改动写入日志(还未持久化commit),并将改动通过heartbeat广播至follower节点。follower节点写了entry之后(此时还未commit),返回ack。leader收到大于集群节点一半的ack之后,认为已经可以commit了,广播commit的通知。最终集群内所有follower触发commit,向leader返回ack。最后leader认为集群已经达成一致性了,向client返回ack
如果集群中产生网络隔离,每个隔离域中会产生一个新的leader,整个集群会存在多个leader。follower少的leader由于获取不到majority ack,他的entry不会被commit。此时client往另一个follower多的leader发送数据改变请求,该隔离域的节点会被commit
此时去掉网络隔离后,之前follower少的隔离域内未commit的entry会被刷成之前follower多的隔离域的entry,随后commit,此时集群再次达成一致性